Graduate Underemployment / Overqualification Prediction
Full machine learning pipeline for predicting overqualification (underemployment) in recruitment using the NGS (National Graduate Survey) structured hiring dataset. Built for the SFU Data Science Student Society ML Hackathon; uses CatBoost with a focus on predictive performance and interpretability (feature importance, optional SHAP).
Preview
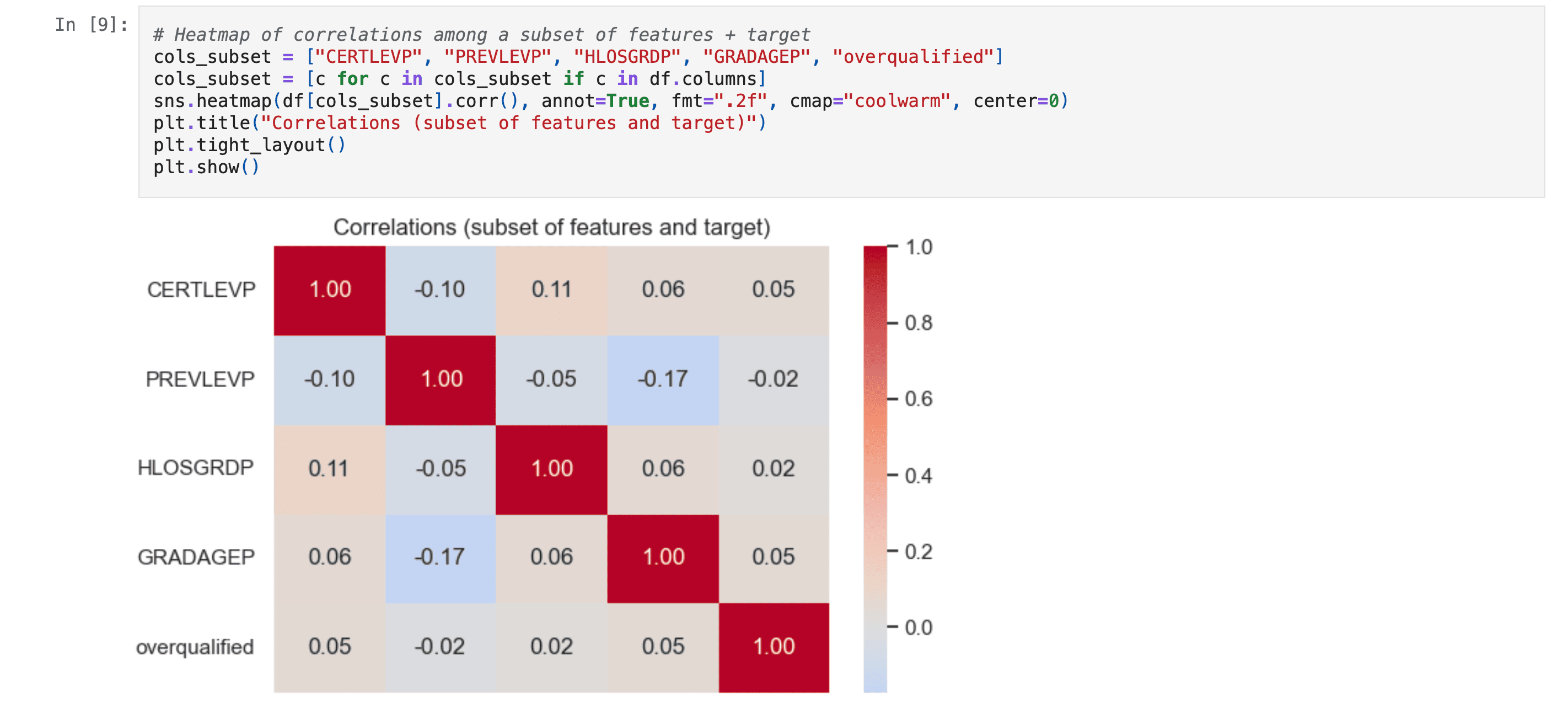
Problem & Context
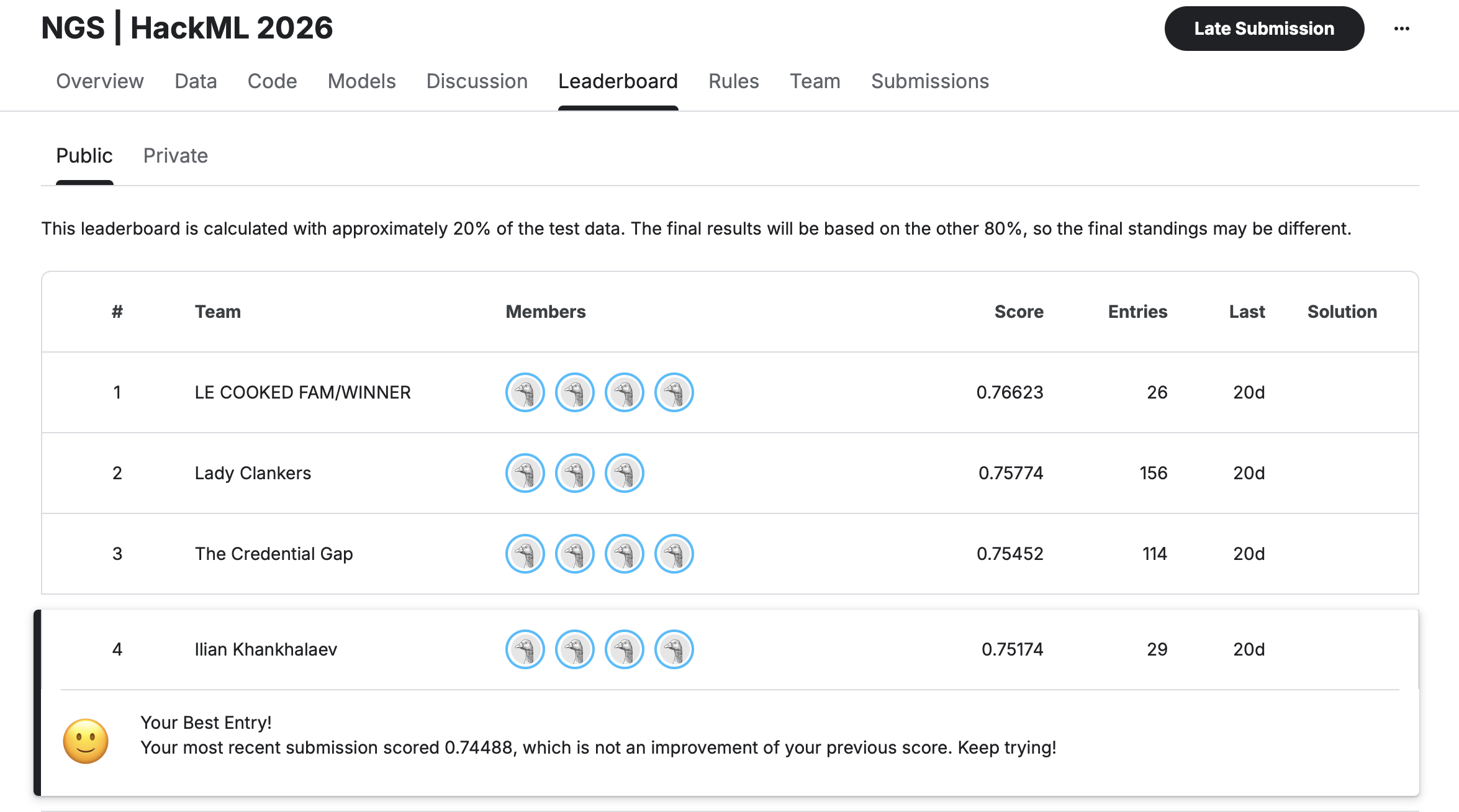
The goal was to build a robust model that accurately estimates overqualification probability from candidate attributes (education, experience, skills, demographics), work with the NGS dataset and its feature structure (survey codes, missing conventions), and train a CatBoost-based model with validation and leaderboard-oriented iteration. The solution achieved 0.75174 accuracy on the Public leaderboard and 0.70511 on the Private leaderboard, placing close to the top-performing teams.
What It Does
- Modular ML pipeline — Clean separation of data loading, preprocessing, feature engineering, model training, evaluation, and prediction in
src/ - NGS-aware preprocessing — Handling of special codes (6, 9, 99) and normalization of mixed-type columns
- CatBoost classifier — Native categorical support, early stopping, configurable hyperparameters
- Stratified K-fold cross-validation and optional grid search for hyperparameter tuning
- Interpretability — Feature importance and optional SHAP integration
- Reproducible workflow —
python3 -m src.trainandpython3 -m src.predictfor end-to-end training and submission - Five Jupyter notebooks — Exploration, preprocessing, training/tuning, evaluation/interpretability, pipeline demo
Tech Stack
Key Takeaways
Structured pipelines and NGS-aware preprocessing were essential for leaderboard performance. CatBoost’s native categorical handling and interpretability (feature importance, SHAP) made it a strong choice for this tabular classification task.