House Price Prediction — v2 Enhanced ML Pipeline
An advanced, modular machine learning pipeline for predicting median house prices in California. Version 2 introduces feature engineering, regularized linear models (Ridge, Lasso), cross-validation, hyperparameter tuning, and a custom Gradient Descent Regressor built from scratch — all organized into reusable source modules.
Preview
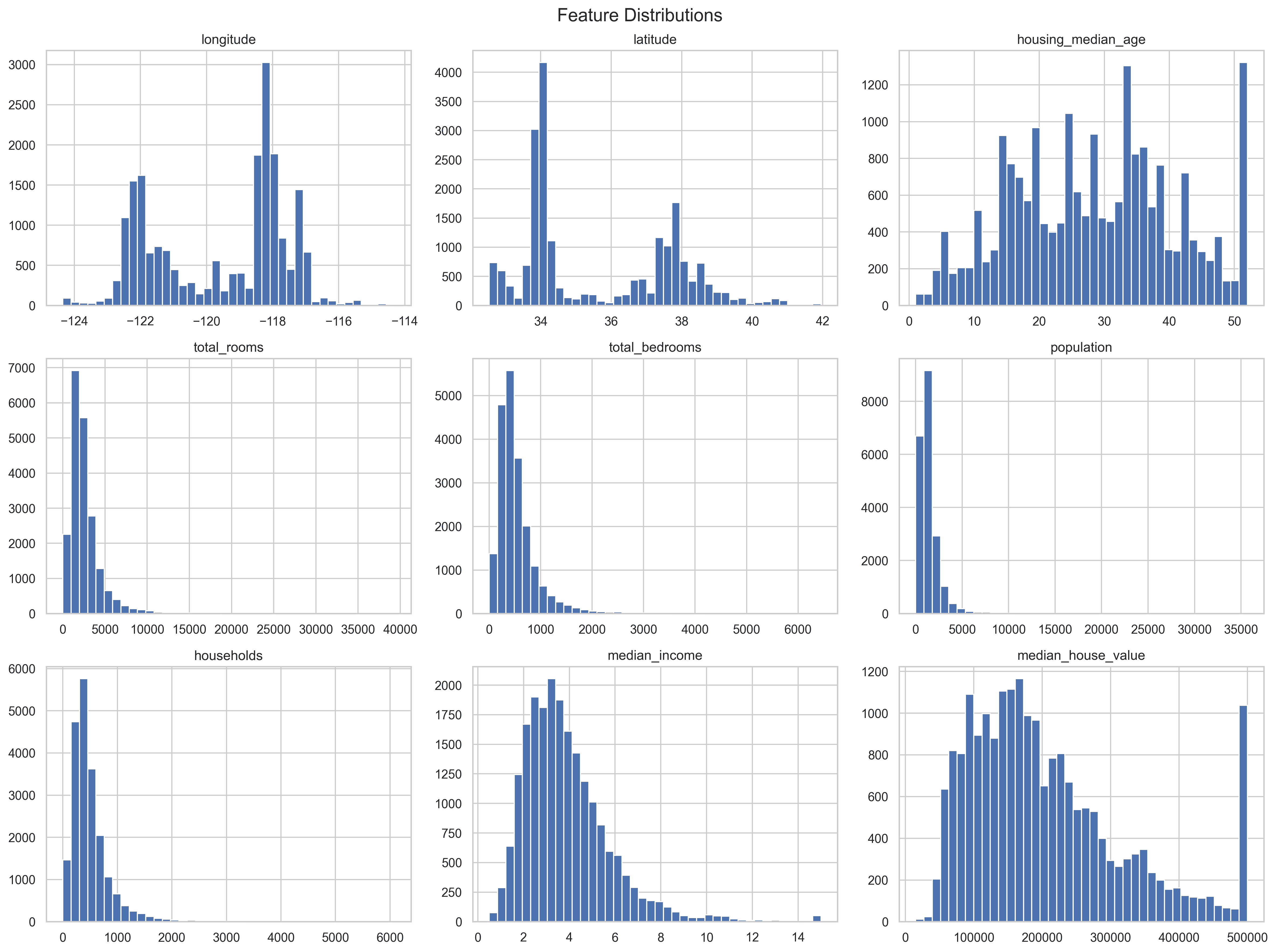
Problem & Context
The goal of v2 is to build a fully modular, extensible ML pipeline for structured tabular data; introduce feature engineering and standardization to improve stability and performance; implement and compare multiple linear models (OLS, Ridge, Lasso, custom Gradient Descent); evaluate robustness through 5-fold cross-validation and hyperparameter tuning; and establish a reproducible training workflow that cleanly separates preprocessing, training, evaluation, and inference.
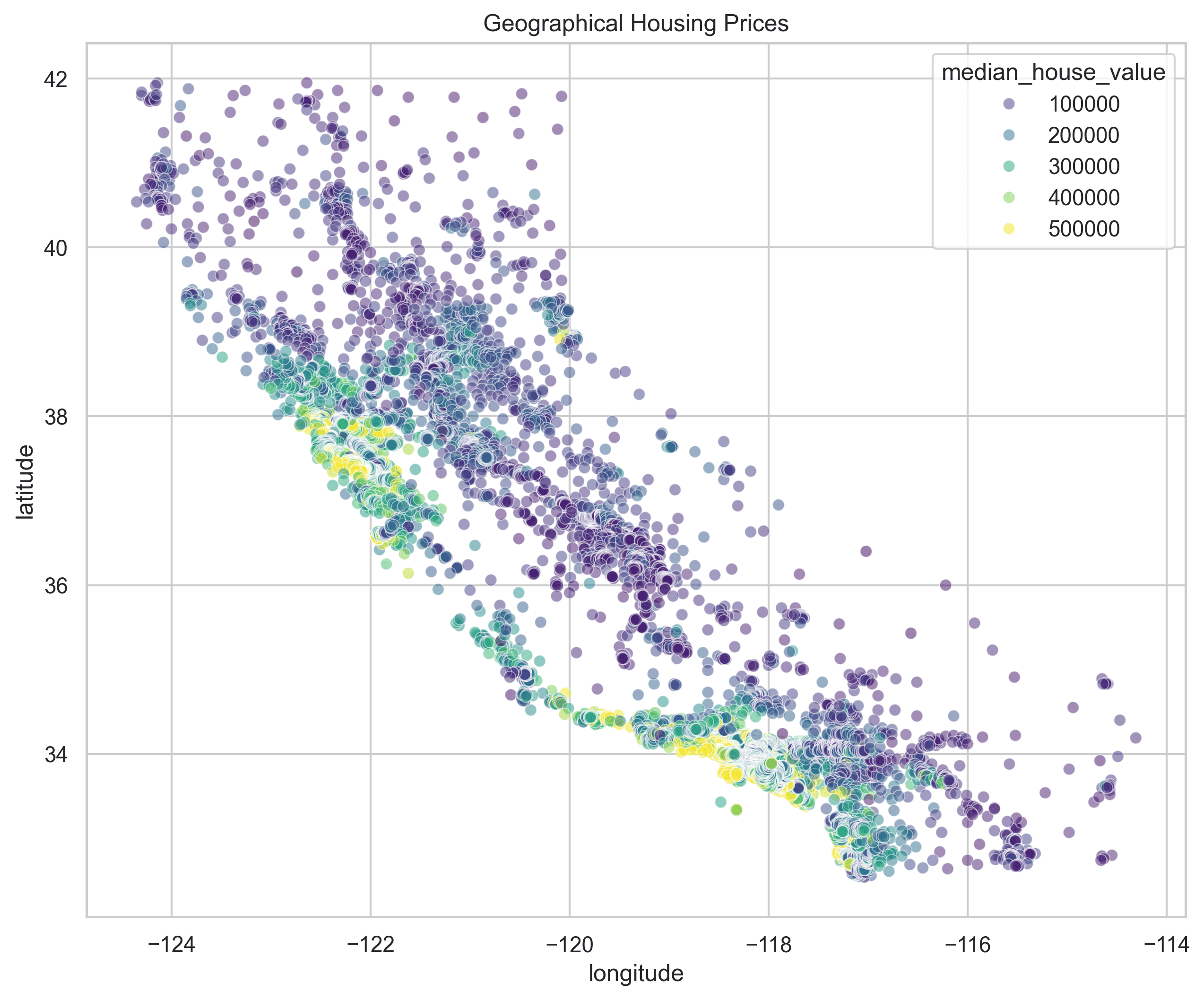
What’s New in v2 (vs v1)
- Feature Engineering — Full transformations and scaling (v1 had minimal)
- Models — Custom Gradient Descent, OLS, Ridge, Lasso (v1 had OLS only)
- Cross-Validation — 5-fold CV for stability analysis (v1 had none)
- Pipeline — Modular Python pipeline in
src/(v1 was notebook-only) - Performance — Lower RMSE after feature engineering and regularization
What I Built
- Custom modular ML pipeline — Clean separation of preprocessing, training, evaluation, and utilities in
src/ - Feature engineering & standardization — Consistent transformations across training and inference
- Multiple linear models — OLS, Ridge (L2), Lasso (L1), plus custom Gradient Descent Regressor with configurable learning rate, iterations, and convergence tracking
- 5-fold Cross-Validation — Model stability and variance assessment
- Hyperparameter tuning — Grid search for regularized models
- Reproducible pipeline — End-to-end training via
python3 -m src.train - Five structured notebooks — Exploration, custom GD evaluation, sklearn baseline, CV comparison, pipeline demo
Results (Summary)
Custom Gradient Descent Regressor: Converged in ~1500 iterations. Test RMSE: ~74.6K USD. Test R²: ~0.57.
The model explains ~57% of variance in housing prices, captures strong linear trends (e.g., median income → price), and misses nonlinear and interaction effects. Full model comparisons (Ridge, Lasso, CV results) are documented in the repository’s reports/report.md.
Tech Stack
Architecture / How It Works
The pipeline runs end-to-end via python3 -m src.train. Data is loaded from data/raw/, preprocessed and feature-engineered dynamically (no persisted processed data), then used to train and evaluate models. The src/ modules handle config, data loading, feature engineering, preprocessing, gradient descent, evaluation, hyperparameter tuning, and model I/O. Notebooks document the full development workflow from exploration through baselines, cross-validation, and pipeline demo.
Key Takeaways
Version 2 demonstrates ML engineering best practices: modularity, reproducibility, and robust evaluation. Feature engineering and regularization improve over the v1 baseline. The custom Gradient Descent implementation reinforces understanding of optimization fundamentals. Future directions include integrated GridSearchCV, nonlinear models (Random Forest, XGBoost), experiment tracking (MLflow, W&B), and production-ready tooling.