Projects — Data, ML & Software
Pipelines, evaluation, and product thinking in practice. Building artifacts informed by real-world constraints.
After Synkron, I wanted to go beyond using machine learning as a black box. I started building systems myself, from data pipelines and model training to full-stack apps that put AI in users' hands. My focus: data, machine learning, and software that solve real problems.
These projects are where theory meets practice. Each one pushes on a different part of the stack: data wrangling and feature engineering, model evaluation and iteration, or end-to-end product design. The goal is not perfection, it's learning how systems fail, scale, and ship.
What I built
Across data, ML, and software, the work falls into three buckets:
- Data & Machine Learning
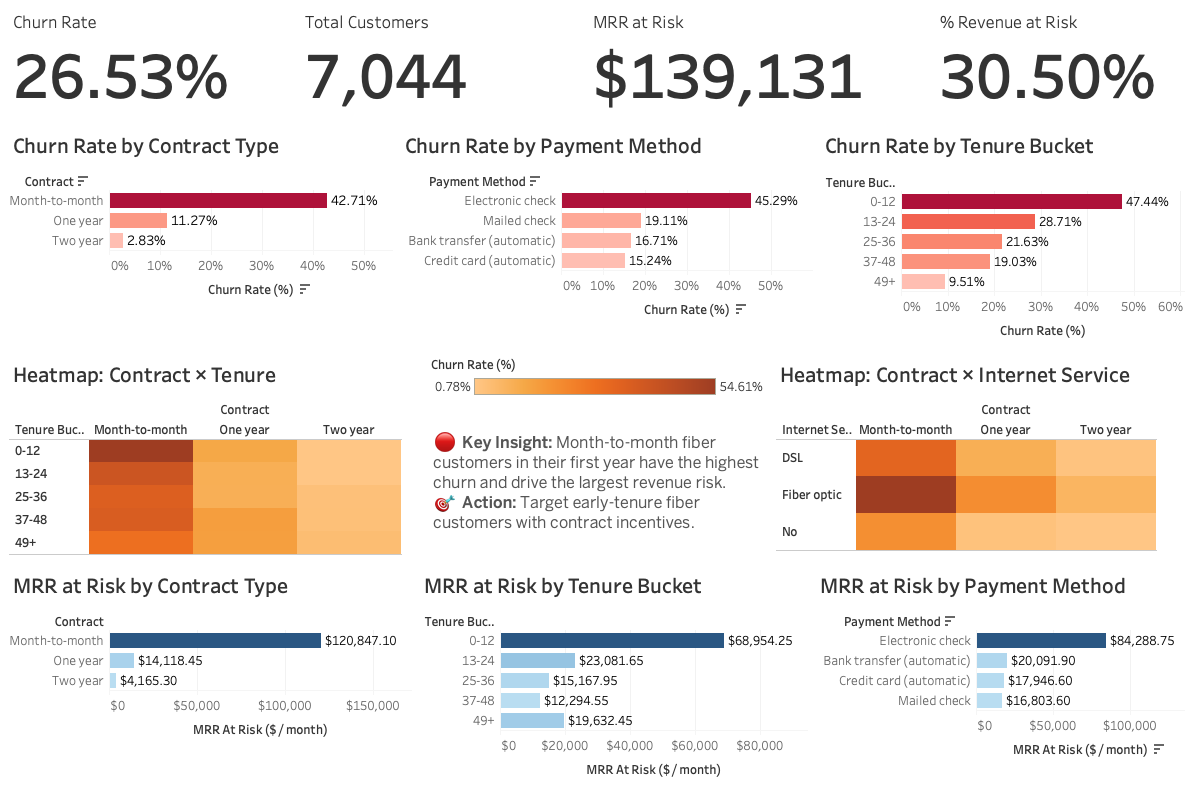
House-Price-ML (v1 baseline and v2 feature engineering) — full ML pipelines from EDA to scikit-learn models. ML Hackathon project (CatBoost for overqualification prediction). - Full-stack / Software
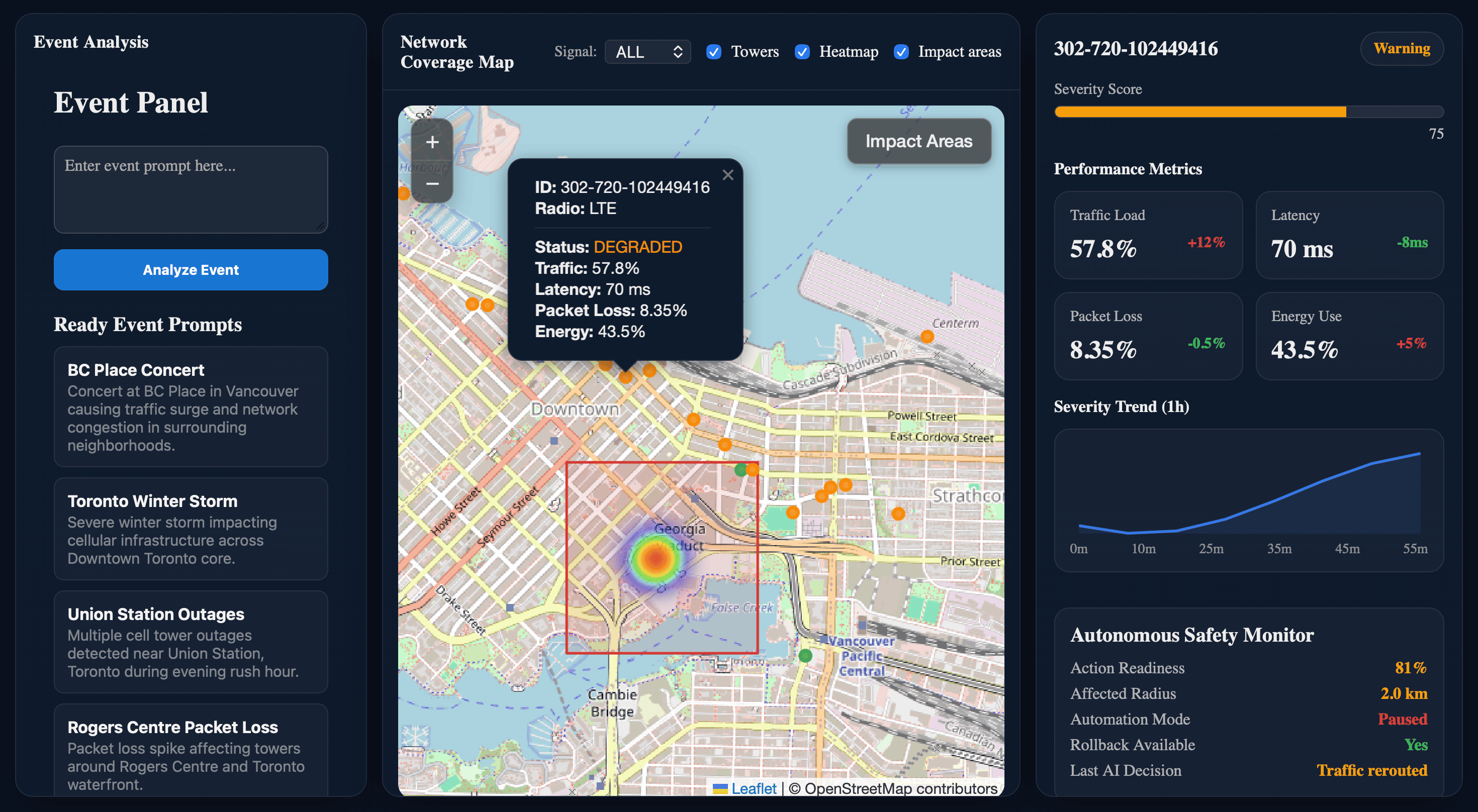
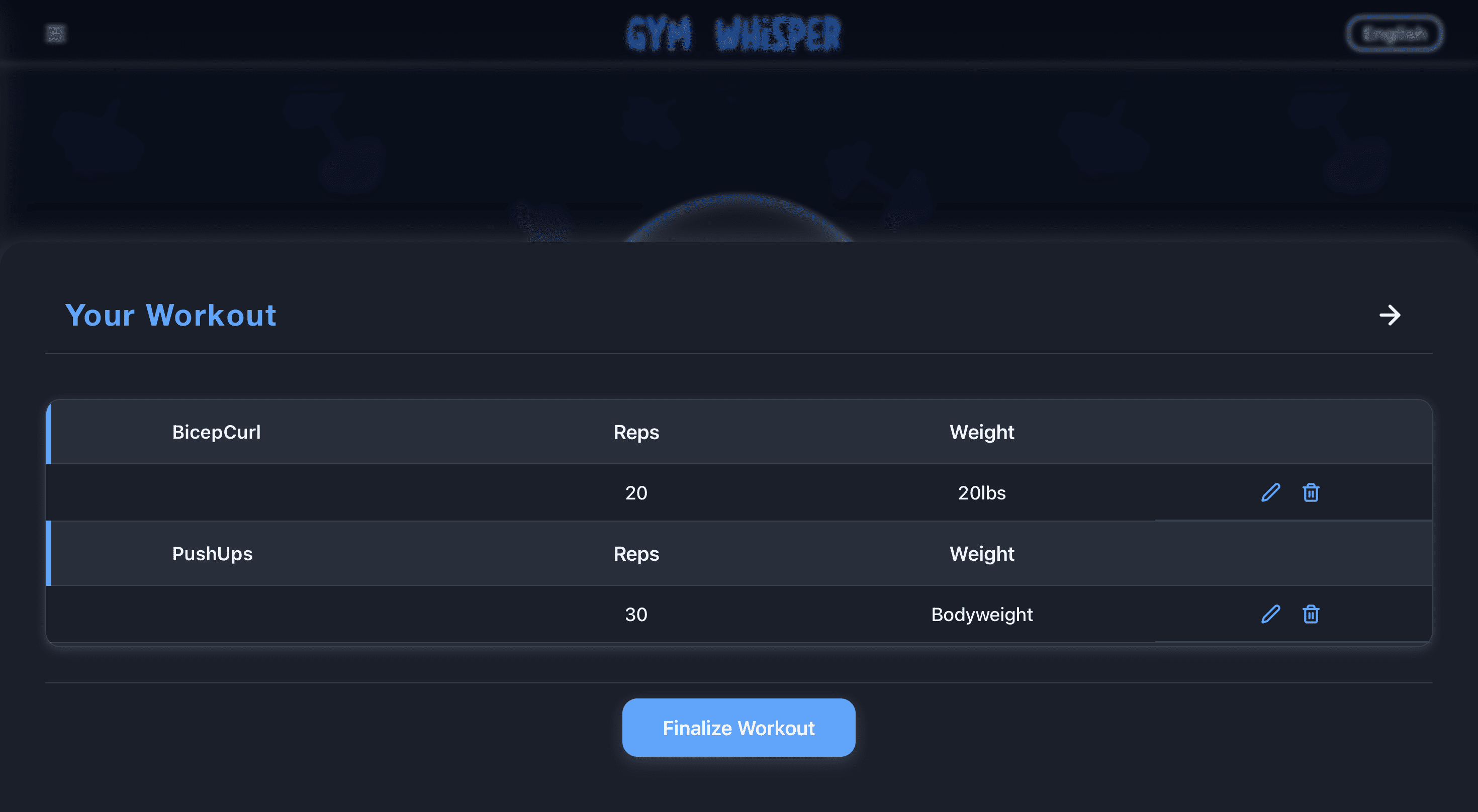
GymWhisper — voice-powered workout tracking (React, Gemini API, speech recognition). TelusGuardAI / Network Impact Analyzer — multi-agent AI for geospatial network outage analysis (React, Flask, Leaflet). - Systems & Coursework
Personal website, portfolio projects, and research on AI in Autonomous Vehicles. Smaller experiments in C, Linux, and CLI tooling.
Tools
Python, SQL, and JavaScript for data and ML. scikit-learn, CatBoost, pandas, NumPy, and Jupyter for modeling and analysis. React, Flask, Leaflet, and Tableau on the product side, plus Git, GitHub Actions, and GitHub Pages to actually ship things. The stack evolves with each project — the constant is thinking in terms of pipelines, evaluation metrics, and user value.
Proof / demos
See the full project catalog with live demos, reports, and write-ups: See all projects →. Highlights include GymWhisper (demo + report), House-Price-ML (report), and TelusGuardAI (demo + report).